What is an SLM?
A Small Language Model (SLM) is tailored to excel in simpler tasks, offering boosted accessibility and user-friendliness for organizations operating with limited resources. Besides, they can be readily fine-tuned to align with specific requirements. Small language models are particularly well-suited for organizations aiming to develop applications capable of operating local devices instead of relying on cloud infrastructure. They are especially beneficial for tasks that do not necessitate extensive reasoning or immediate responses.
Reasons to use SLMs
Given the growing popularity and applicability of SLMs across various domains, particularly in areas like sustainability and the volume of data required for training, there are multiple reasons for employing them.
What is Phi-3?
Microsoft has a suite of small language models (SLMs) known as ‘Phi,’ demonstrating outstanding performance across various benchmarks. Microsoft’s recent release is Phi-3, a series of open AI models. The Phi-3 models represent a prototype of capability and cost-effectiveness among small language models (SLMs), exceeding models of equivalent and larger sizes across the spectrum of coding, language, reasoning, and mathematical standards. This launch broadens the array of high-calibre models accessible to customers, providing them with more practical options as they craft and construct generative AI applications.
Phi-3-mini, a 3.8B language model, is accessible through Microsoft Azure AI Studio, Hugging Face, and Ollama. It is offered in two context-length variations—4K and 128K tokens. Notably, it is the first model within its category to support a context window of up to 128K tokens with minimal impact on quality. Furthermore, it is instruction-tuned, implying that it has been trained to comprehend and adhere to diverse instructions, mirroring natural human communication patterns. This ensures that the model is readily deployable straight out of the box. Phi-3-mini is available on Azure AI to leverage the deploy-eval-finetune toolchain, and it is also accessible on Ollama for developers to execute locally on their laptops.
Features of Phi-3
Phi-3 models exhibit distinctive superiority over language models of comparable and larger dimensions on key benchmarks, showcasing the following features:
Snowflake meets Phi-3: Advantages
The key pain point about LLMs is the computing required to host and run them. Setting up a dozen GPUs to run models can be expensive and complex. There’s where Snowflake steps up. Snowflake’s compute pool option enables users to easily and quickly set up and manage compute clusters. Phi-3 comes into the picture because of its cost-effective GPU utilization.
Can you imagine a situation where your language model only requires less than 3GB of GPU memory for inference? Well, now it’s possible, all thanks to Phi-3. It’s a state-of-the-art SLM that produces excellent results over GP3.5 and Mistral 8x7B, which are much bigger models. This opens the door for more cost-effective solutions to be brought up in the AI space. Add Snowflake for hosting; you have an excellent setup to host, test, and build AI applications. Read below how Beinex managed to run Phi-3 on Day 0 in Snowflake.
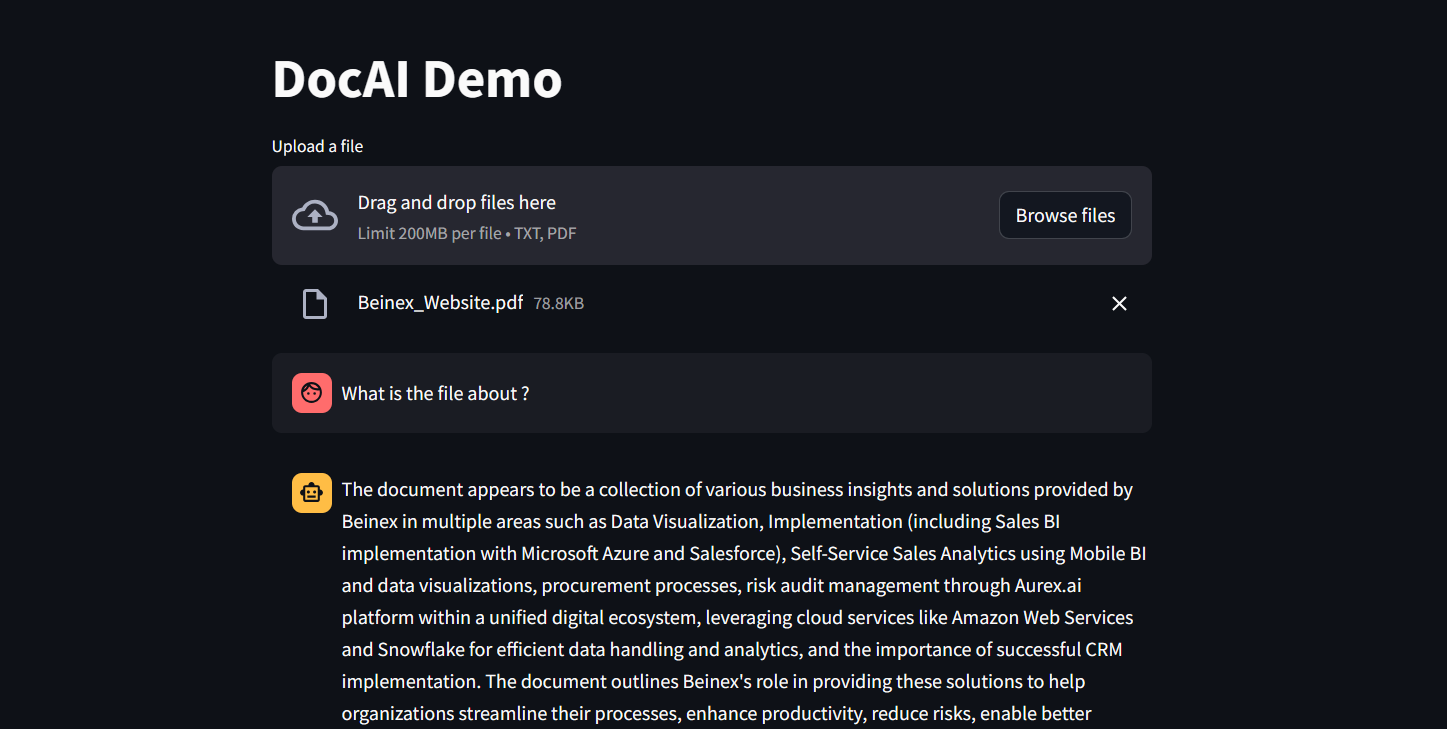
Figure 1: DocAI running on Phi-3
Implementing Phi-3 on Snowflake: What Beinex Did and How Beinex Did it?
Beinex has seamlessly integrated Phi-3 into Snowflake to help enterprises unlock their data’s full potential through advanced language processing capabilities and enhance decision-making with deeper insights. The integration facilitates Snowflake users to:
Here’s a detailed guide on implementing Phi-3 on Snowflake:
Step 1: Create Necessary Objects
— Run by ACCOUNTADMIN to allow connecting to Hugging Face to download the model
— Stage to store LLM models
CREATE STAGE <stagename> IF NOT EXISTS models
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE=‘SNOWFLAKE_SSE’);
— Stage to store YAML specs
CREATE STAGE <stagename> IF NOT EXISTS specs
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE=‘SNOWFLAKE_SSE’);
— Image repository
CREATE OR REPLACE IMAGE REPOSITORY images;
— Compute pool to run containers
CREATE COMPUTE POOL GPU_NV_S
MIN_NODES = 1
MAX_NODES = 1
INSTANCE_FAMILY = GPU_NV_S;
Step 2: Docker Image Code – ollama
FROM ollama/ollama
RUN $(ollama serve > output.log 2>&1 &) && sleep 10 && ollama pull phi3 && pkill ollama && rm output.log
ENTRYPOINT [“ollama”]
CMD [“serve”]
Step 3: Tag and Push the Docker Image
docker tag ollama <SNOW_ORG-SNOW_ACCOUNT>.registry.snowflakecomputing.com/db/schema/image respository /ollama
docker push <SNOW_ORG-SNOW_ACCOUNT>.registry.snowflakecomputing.com db/schema/image repository /ollama
Step 4: Docker Image – UDF
FROM python:3.11
WORKDIR /app
ADD ./requirements.txt /app/
RUN pip install –no-cache-dir -r requirements.txt
ADD ./ /app
EXPOSE 5000
ENV FLASK_APP=app
CMD [“flask”, “run”, “–host=0.0.0.0”]
App.py content is given below :
from flask import Flask, request, Response, jsonify
import logging
import re
import os
from openai import OpenAI
client = OpenAI(
base_url=‘http://ollama:11434/v1’,
api_key=“EMPTY”,
)
model = “phi3”
app = Flask(__name__)
app.logger.setLevel(logging.ERROR)
def extract_json_from_string(s):
logging.info(f”Extracting JSON from string: {s}”)
# Use a regular expression to find a JSON-like string
matches = re.findall(r”\{[^{}]*\}”, s)
if matches:
# Return the first match (assuming there’s only one JSON object embedded)
return matches[0]
# Return the original string if no JSON object is found
return s
@app.route(“/”, methods=[“POST”])
def udf():
try:
request_data: dict = request.get_json(force=True) # type: ignore
return_data = []
for index, col1 in request_data[“data”]:
completion = client.chat.completions.create(
model=model,
messages=[
{
“role”: “system”,
“content”: “You are a bot to help extract data and should give professional responses”,
},
{“role”: “user”, “content”: col1},
],
)
return_data.append(
[index, extract_json_from_string(completion.choices[0].message.content)]
)
return jsonify({“data”: return_data})
except Exception as e:
app.logger.exception(e)
return jsonify(str(e)), 500
Step 6: YAML File
spec:
containers:
– name: ollama
image: <SNOW_ORG-SNOW_ACCOUNT>.registry.snowflakecomputing.com/ db/schema/image respository /Phi3
resources:
requests:
nvidia.com/gpu: 1
limits:
nvidia.com/gpu: 1
env:
NUM_GPU: 1
MAX_GPU_MEMORY: 24Gib
volumeMounts:
– name: llm-workspace
mountPath: /<stage name>
– name: udf
image: <SNOW_ORG-SNOW_ACCOUNT>.registry.snowflakecomputing.com/ db/schema/image respository /ollama_udf
endpoints:
– name: chat
port: 5000
public: false
– name: llm
port: 11434
public: false
volumes:
– name: llm-workspace
source: “@<llm stage_name>“
Step 7: Upload YAML File and Create Service
Upload the YAML file to the created stage, where the stage name in the YAML file should match the stage created in Step 2.
— Create service
create service phi3
IN COMPUTE POOL <name of compute pool created>
FROM @dash_stage
SPECIFICATION_FILE = ‘<name of yaml file uploaded>’;
Step 8: Create Service Function
Create a service function on the service (after it starts).
create or replace function phi3chat(prompt text)
returns text
service= phi3
endpoint=chat;
Check Service Status
Use the following command to check the status of the service:
SELECT
v.value:containerName::varchar container_name,
v.value:status::varchar status,
v.value:message::varchar message
FROM (
SELECT parse_json(system$get_service_status(‘<service name>’))
) t,
LATERAL FLATTEN(input => t.$1) v;
Benefits of Running Phi-3 on Snowflake
1. Cost-Effectiveness and Efficiency:
2. Compatibility with Smaller GPUs:
3. Exceptional Performance:
4. Faster Response Times:
SLM vs LLM
The choice between small and large language models hinges on organizational needs, task complexity, and resource availability.
LLMs excel in applications requiring the orchestration of intricate tasks, encompassing advanced reasoning, data analysis, and contextual comprehension.
On the other hand, SLMs present viable options for regulated industries and sectors facing scenarios necessitating top-tier results while maintaining data within their premises.
Both large and small language models possess distinct strengths and applications. While large language models thrive in managing complex workflows, small language models deliver impressive performance despite their compact size.
While some customers may exclusively require small models, others may favour larger models, with many seeking to integrate both types in various configurations. Ultimately, the optimal selection depends on the unique context and objectives of the organization. Besides transitioning from large to small models, the trend is evolving towards a diversified portfolio of models. This means that instead of relying on a single model, customers can choose from various models with different sizes, capabilities, and resource requirements. This empowers customers to decide the best model for their scenario, balancing performance and resource constraints.