البيانات الضخمة هي حجم كبير من البيانات ومجموعات البيانات التي تأتي في أشكال متنوعة ومصادر متعددة. لقد أدركت العديد من المنظمات مزايا جمع أكبر قدر ممكن من البيانات. هنا، يتحدث سانشيت عن كيف يمكن للمؤسسات الاستفادة من تحليلات البيانات الضخمة لتحويل تيرابايت من البيانات إلى رؤى قابلة للتنفيذ وإطلاق العنان لإمكانات البيانات الضخمة بغرض تحقيق الاستفادة القصوى. واصل القراءة
1.من فضلك أخبرنا عن تعيينك ودورك ومسؤولياتك في بينيكس.
أنا أعمل حاليًا بصفتي مديرًا. مسؤولياتي تشمل:
- مساعدة العملاء في طلباتهم الخاصة
- إدارة ارتباطات متعددة
- دعم فريق ما قبل البيع في عروضهم للعملاء الجدد
- تقديم الخبرة الفنية لجميع الزملاء والعملاء
كيف يمكنك التوفيق بين البيانات الضخمة وتصور البيانات ذات الصلة؟
عند التفكير في حل للبيانات الضخمة، يجب أن تضع في اعتبارك بنية نظام ذكاء الأعمال التقليدي وكيف يتم تشغيل البيانات الضخمة. حسنًا، لقد عملنا مع البيانات المهيكلة القادمة بشكل أساسي من نظام إدارة قواعد البيانات المرتبطة (بنية الجدول القائمة على الصفوف) التي تم تحميلها في مستودع البيانات، وهي جاهزة للتحليل وعرضها على مستخدمي الأعمال.
تسمح حلول البيانات الضخمة للنظام بمعالجة كميات أكبر من البيانات بشكل أسرع، والتي يمكن أن تكون أكثر تنوعًا، مما يتيح الفرصة لاستخراج المعلومات بكفاءة وأمان من البيانات التي لا يستطيع الحل التقليدي القيام بها.
بالإضافة إلى ذلك، يسمح استخدام البيانات الضخمة لهيكل الأجهزة بالنمو أفقيًا، وهو أكثر اقتصادًا ومرونة. إذًا، كيف تدخل البيانات الضخمة هذا النظام المتكامل؟ تتشابه مفاهيم التصميم الرئيسية إلى حد كبير، ولكن هناك تغييرات كبيرة. الاختلافات الرئيسية هي مجموعة جديدة كاملة من مصادر البيانات، على وجه التحديد بيئة جديدة تمامًا لتخزين البيانات ومعالجتها.
يستخدم تابلو برامج تشغيل تستفيد من معيار برمجة اتصال قاعدة البيانات المفتوح كطبقة ترجمة بين واجهات بيانات لغة الاستعلام الهيكلية ولغة الاستعلام الهيكلية التي توفرها أنظمة البيانات الضخمة هذه. باستخدام اتصال قاعدة البيانات المفتوحة، يمكنك الوصول إلى أي مصدر بيانات يدعم معيار لغة الاستعلام الهيكلية ويقوم بتنفيذ اتصال قاعدة البيانات المفتوح. واجهة برمجة تطبيق بالنسبة إلى هادوب، يتضمن ذلك واجهات مثل لغة استعلام هايف، ولغة استعلام إمبالا ولغة استعلام بيج، ولغة استعلام سبارك. لتحقيق أفضل أداء ممكن، نقوم بضبط لغة الاستعلام الهيكلية التي ننشئها وندفع التجميعات والمرشحات وعمليات لغة الاستعلام الهيكلية الأخرى إلى منصات البيانات الضخمة. بناء التصورات باستخدام اتصال قاعدة البيانات المفتوح المباشر من إمبالا / هايف، يمكن لـ تابلو الاتصال وتشغيل استعلامات أسرع في الاستخراج والعلاقات الفورية.

المصدر: https://www.clearpeaks.com/big-data-ecosystem-spark-and-tableau/
كيف تعرف الفئة التي تختارها وتتجنبها عند تصور البيانات الضخمة؟
حسب الحاجة هو أفضل بنية في أي وقت.
في أنماط تصميم الاستيعاب والتحميل الحديثة، غالبًا ما تكون وجهة البيانات الأولية من أي حجم أو شكل عبارة عن بحيرة بيانات: مستودع تخزين يحتوي على كمية هائلة من البيانات بتنسيقها الأصلي، سواء كانت منظمة أو شبه منظمة أو غير منظمة.
يتم إنشاء بيانات البث بشكل مستمر من خلال الأجهزة والتطبيقات المتصلة، مثل الشبكات الاجتماعية، والعدادات الذكية، والتشغيل الآلي للمنزل، وألعاب الفيديو، وأجهزة استشعار إنترنت الأشياء. في كثير من الأحيان، يتم جمع هذه البيانات عبر خطوط أنابيب البيانات شبه المنظمة.
لا يزال يتعين علينا التأكد من أننا نتجنب إدخال جميع البيانات في أي تطبيق تصويري؛ كلما قلت البيانات سيكون وقت الاستجابة أقل. يساعد جلب المعلومات ذات الصلة على زيادة أداء الاستعلام ويمكّنك من العثور على الإجابات التي تبحث عنها بسرعة.
4. كيف تقوم بإعداد البيانات الضخمة للتصور والتحليل؟
توجد اليوم مجموعة متنوعة من الخيارات لدفق البيانات، بما في ذلك أمازون كنسيس وستورم وفلوم وكافكا وسريان داتا إنفورماتيكا فايب.
توفر بحيرات البيانات أيضًا آليات معالجة محسّنة عبر واجهات برمجة التطبيقات أو لغات شبيهة بلغات الاستعلام الهيكلية لتحويل البيانات الأولية باستخدام وظيفة “المخطط عند القراءة”. بمجرد وصول البيانات إلى بحيرة البيانات، يجب استيعابها وإعدادها للتحليل. لدى تابلو شركاء مثل إنفورماتيكا وألتريكس وترايفاكتا وداتامير الذين يساعدون في هذه العملية ويعملون بسلاسة مع تابلو. بالتناوب، لإعداد بيانات الخدمة الذاتية، يمكنك استخدام تابلو التحضيري.
5.. ما مدى جودة تابلو عندما يتعلق الأمر بتصور البيانات
قد تكون منصة التحليلات الحديثة مثل تابلو هي المفتاح لإطلاق إمكانات البيانات الضخمة من خلال اكتشاف الرؤى، ولكنها لا تزال مجرد أحد المكونات الحاسمة لبنية منصة البيانات الهامة الكاملة. قد يبدو تجميع خط أنابيب كامل لتحليلات البيانات الضخمة بمثابة تحدٍ.
الخبر السار هو أنك لست بحاجة إلى بناء النظام المتكامل بأكمله قبل أن تبدأ، ولا تحتاج إلى دمج كل مكون على حدة لاستراتيجية كاملة للانطلاق. يناسب تابلو بشكل جيد نموذج البيانات الضخمة لأنه يعطي الأولوية للمرونة – القدرة على نقل البيانات عبر الأنظمة الأساسية، وتعديل البنية التحتية عند الطلب، والاستفادة من أنواع البيانات الجديدة، وتمكين المستخدمين الجدد وحالات الاستخدام.
نعتقد أن نشر حل تحليلات البيانات الضخمة لا ينبغي أن يملي عليك البنية التحتية أو الإستراتيجية الخاصة بك، ولكن يجب أن يساعدك على الاستفادة من الاستثمارات التي قمت بها بالفعل، بما في ذلك تلك التي لديها تقنيات مشتركة ضمن النظام المتكامل الشامل للبيانات.
التخزين والمعالجة
يسمح هادوب بالتخزين منخفض التكلفة وأرشفة البيانات لتفريغ البيانات التاريخية القديمة من مستودع البيانات إلى مخازن باردة عبر الإنترنت في بنية تحليلات حديثة. كما أنها تستخدم لإنترنت الأشياء وعلوم البيانات وحالات استخدام التحليلات غير المنظمة. يوفر تابلو تصالاً مباشرًا بجميع توزيعات هادوب الرئيسية مع كلاوديرا عبر إمبالا وهورتن وركس عبر هايف ومابر عبر أباتشي دريل.
ندفة الثلج أو سنوفليك هو أحد الأمثلة على مستودع بيانات المؤسسة المستند إلى السحابة الأصلية المستند إلى لغة الاستعلام الهيكلية مع موصل تابلو الأصلي.
يمكن أيضًا استخدام مخازن الكائنات، مثل خدمة التخزين البسيط من خدمات الويب من أمازون (إس 3) وقواعد بيانات بلا لغة استعلام هيكلية ذات المخططات المرنة كمخازن بيانات. يدعم تابلو خدمة بيانات أثينا من أمازون للاتصال بـأمازون إس 3 ولديه العديد من الأدوات المتعلقة بقواعد بيانات NoSQL أو قواعد البيانات التي ليس لها لغة استعلام هيكلية. تتضمن أمثلة قواعد بيانات التي لا لغة استعلام هيكلية لها التي تُستخدم غالبًا مع تابلو، على سبيل المثال لا الحصر، مونجو دي بي وداتا ستاكس ومارك لوجيك.
تقدم منصة داتا بريكس لعلوم وهندسة البيانات معالجة البيانات على سبارك، وهو محرك شائع لمعالجة البيانات الموجهة نحو الدُفعات والتفاعلية. من خلال موصل أصلي لسبارك، يمكنك تصور نتائج نماذج التعلم الآلي المعقدة من داتا بريكس في تابلو.
تسريع الاستعلام
ما هي سرعة لغة الاستعلام الهيكلية التفاعلية؟ لغة استعلام هيكلية، بعد كل شيء، هي القناة لمستخدمي الأعمال الذين يرغبون في استخدام البيانات الضخمة للحصول على لوحات معلومات وتحليلات استكشافية أسرع وأكثر قابلية للتكرار. أدت هذه الحاجة إلى السرعة إلى اعتماد قواعد بيانات أسرع تستفيد من تقنية الذاكرة والمعالجة المتوازية الضخمة مثل إكساسول وذاكرة لغة الاستعلام الهيكلية، المتاجر المستندة إلى هادوب مثل كودو والتقنيات التي تتيح استعلامات أسرع مع المعالجة المسبقة مثل فيرتيكا. باستخدام محركات لغة استعلام هيكلية على هادوب مثل أباتشي إمبالا وهايف لونج ليف أند بروسيس وبريستو وفينيكس ودريل وتقنيات أولاب على هادوب مثل أت سكيل وبيانات جيثرو ورؤى كايفوس، تعمل مسرعات الاستعلام هذه على زيادة وضوح الخطوط الفاصلة بين المستودعات التقليدية وعالم البيانات الضخمة.
. ما الأشياء التي يجب مراعاتها عند استخدام تابلو وتصور البيانات الضخمة؟
على الرغم من عدم وجود بنيتين مؤسستين متماثلتين، إلا أن ملاحظة الأنماط المتشابهة وما تشترك فيهما يمكن أن يساعدك في وضع استراتيجية لمنصة تحليلات البيانات الضخمة الخاصة بك. إليك ما لاحظناه باستمرار في بنيات تحليلات البيانات الضخمة الناجحة:
- طبقة تخزين: قد تتطلب إستراتيجية البيانات الخاصة بك بيئات تخزين متعددة ولكن يجب أن تشتمل على بيانات منظمة وشبه منظمة وغير منظمة.
- محركات الحوسبة التي لا تحتوي على خادم: بعض عمليات التحضير والتحليل للبيانات ، ومحركات الحوسبة الأخرى للاستعلام. تسمح الطبيعة الديناميكية للحوسبة بدون خادم بمزيد من المرونة، حيث لا توجد حاجة لتخصيص الموارد مسبقًا.
- دعم الحجم والسرعة والتنوع: لا ينطبق هذا على البيانات فحسب، بل على تعقيدها المتزايد وعدد حالات الاستخدام، والتي لم يتم اكتشاف بعضها بعد.د
- الأداة المناسبة للوظيفة: من الضروري تكييف مكونات البنية الخاصة بك للتعامل مع إستراتيجية البيانات الفريدة الخاصة بك. ومع ذلك، من المهم أيضًا أن تظل رشيقًا في تغيير احتياجات العمل.
- الحوكمة والأمن على مستوى المؤسسة: على الرغم من أننا لم نخوض في الكثير من التفاصيل في هذه المجالات، إلا أن الأمان والحوكمة أساسيان لضمان قابلية التوسع والاستخدام المناسب لبياناتك.
- الوعي بالتكلفة: ضع التكلفة في الاعتبار عند التفكير في القوة والمرونة اللازمتين لبنية بياناتك المهمة. توفر السحابة قدرًا كبيرًا من المرونة للنمو، لكنك ستحتاج إلى النظر في الآثار المالية لتخزين البيانات ومعالجتها، والتزامن، والتأخر، وحالات استخدام التحليلات، وما إلى ذلك.
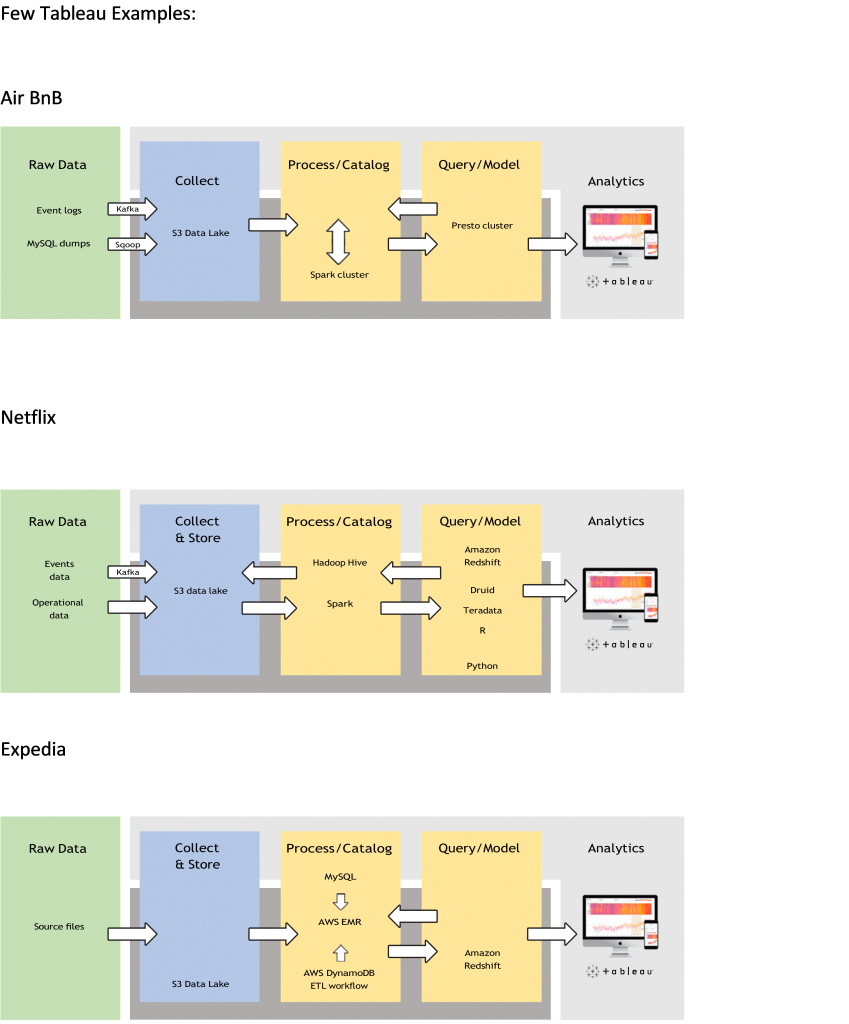
المصدر: https://www.tableau.com/sites/default/files/2021-02/EN_tableau_big_data_overview_whitepaper.pdf